Programming Language Design in the Era of LLMs: A Return to Mediocrity?
programming_languages code llm perspectives
The most exciting part of Programming Languages (PL) research for me has always been in Programming Language Design.
By carefully crafting a language with a syntax and semantics tailored for a specific domain, PL designers can provide an interface for end users that seamlessly aligns with the sensibilities and intuitions of practitioners, allowing users to focus on the "interesting" parts of a problem and tackle larger and more complex problems.
Instead of writing a verbose sequence of API calls to display a dialog to a user in a video game:
# example code for a VN
character.draw("alice", character.LEFT, 0.1)
character.draw("bob", character.RIGHT, 0.1)
character.say("alice", "hello there!")
character.say("bob", "hi!")
character.state("alice", "sad")
character.say("alice", "did you hear the news?")
A DSL instead allows designers to focus on the high-level of what the conversation should be:
# example DSL for dialog
[ alice @ left in 0.1, bob @right in 0.1 ]
alice: hello there!
bob: hi!
alice[sad]: did you hear the news?...
By encoding the "common sense rules" of a domain into the language itself, we can make writing incorrect programs impossible, and eliminate cognitive load and minimise the surface area for bugs and exploits.
A DSL for every domain. When you have eliminated all that is incorrect, then whatever remain, however complex, esoteric or convoluted, simply must be correct.
This has been a fun, exciting and impactful thread of research for the past several decades, but it would be remiss of me at this point to not mention the "e-LLM-ephant" in the room. It has only been a few years, and LLMs and LLM-generated code has already permeated widely across the software ecosystem and continuously forces developers to reevaluate their preconceptions of what is and isn't possible for a machine to generate. Namely, this also includes problems that we might previously have sought to tackle with language design (eliminating boilerplate, capturing conventions or common sense etc.).
This emerging landscape holds a lot of potential, and there are many interesting questions in asking how LLMs can contribute to software development, but as I watch, I am also noticing a worrying trend of LLM developments supplanting advances and interest in the design of DSLs: why craft a DSL that eliminates all boilerplate when an LLM can generate whatever code you need?
Is there a future for Language Design in this new era of LLMs? The point of this blog post is to present ysome thoughts I've been thinking about in this emerging space, prompt for discussion, and outline some potential ways forward language design can co-exist and collaborate with the advances in LLMs.
The LLM Problem, or, rather, Everything is Easier in Python
Let's start with what I see as the biggest problem that the introduction of LLMs is presenting to language design: everything is easier in Python.
That's a little hyperbolic, but what I'm really getting at here is that LLMs have been consistently found to have substantially higher efficiacies when operating in programming languages that are well represented within their training set – think languages like Python, Javascript, Typescript etc.
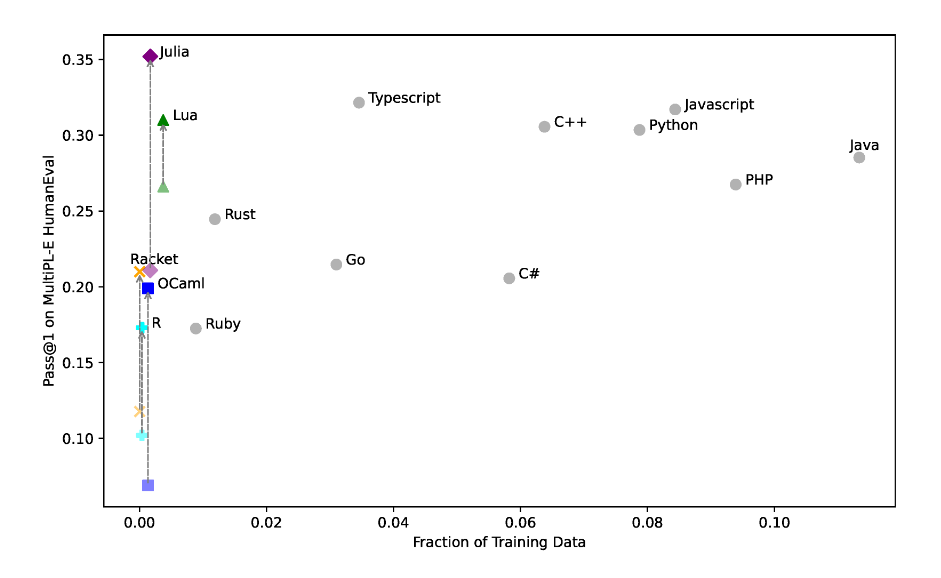
For example, the above graph taken from the paper "Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs" (2024) shows the performance of one of the LLM models (StarCoderBase-15B) on solving programming tasks in several languages against the proportion of the training data represented by files from that language.
The paper presents a technique for improving the performance of these "low-reseource" languages by synthetically generating data, and so the upward lines in this graph represent improvements after fine-tuning using this data, but such transformations have only been applied to smaller models, and certainly nothing at the scale of the production models (ChatGPT, CoPilot, Gemini, Claude etc.) that are the most actively used nowadays.
Looking at the original points in this data, the graph plots a bleak picture: as languages become more niche and specific, the performance of these models drops off a cliff and becomes abysmal — and bear in mind, even these "low-resource" langauges themselves are in their own right, production, industrial systems with millions of users; just not producing enough code for the LLM to do well on them.
If the performance of LLMs drop so sharply even for these general purpose languages, then what can anyone expect from running an LLM on a domain specific language?
Suddenly the opportunity cost for a DSL has just doubled: in the land of LLMs, a DSL requires not only the investment of build and design the language and tooling itself, but the end users will have to sacrifice the use of LLMs to generate any code for your DSL.
This brings me to my biggest fear moving forward: will DSLs stagnate? Will anyone bother writing DSLs if using a niche language forces them to elide any use of LLMs? or has the barrier to entry to DSL design simply just jumped up, where now developers will have to work extra hard to build DSLs that justify losing the ability to use LLMs with your DSL?
Emerging Directions of Language Design in the Land of LLMs
Okay, so with the doomer-posting out of the way, in this section I want to take a little bit more of a more optimistic perspective and think about ways in which language design might evolve and adjust to work in cooperation with LLMs.
So far, there are three interesting directions that I immediately see for the future, but if you have more I'd love to hear about them!
Language Design Direction 1: Teaching LLMs about DSLs (through Python?)
Okay, so the problem with using LLMs on DSLs is that, by their very nature, the syntax and semantics of a DSL will differ substantially from general programming languages. This means that without further context, it can be challenging for an LLM to understand what constructs in a DSL mean and how they should be used together to achieve different programming tasks…
So… how about we give them that context?
I've seen a trend in recent papers such as Verified Code Transpilation with LLMs (2024) where researchers have had success in generating expressions in niche languages (in this case, logical invariants) by instead asking the LLM to generate expressions in a well-known language (in this case, Python), and manually translating to the obscure language of interest.
In the mentioned paper, the authors want to use LLMs to automatically transpile tensor-processing code into different DSLs. In order to ensure that the code is correct, they also ask the LLM to generate invariants that can be used to prove equivalence of both programs:
# example invariant from the paper Verified Code Transpilation with LLMs
def invariant_outer(row, col, b, a, out):
return row >= 0 and row <= len(b) and
out == matrix_scalar_sub(255, matrix_add(b[:i], a[:i])
The key trick in this paper is the use of Python as an intermediate language, where the authors ask LLMs to generate code in restricted subsets of python first, and then write programs to "lift" these python expressions into their DSLs of choice. In this way, the authors can effectively use LLMs to generate code for bespoke DSLs without having to do expensive fine-tuning steps or retraining the model.
Generalising this idea and broadening to the problem of language design in the big, the question I'd like to pose is, can we do this kind of translation automatically? For example, can we create DSL design frameworks that also come with LLM-friendly python descriptions of their semantics? Maybe we can produce frameworks that will test that these python encodings have the same behaviour as the code they model, can we automatically generate the python descriptions from the implementation of the DSL itself?
Language Design Direction 2: Bridging Formal and Informal with LLMs in DSLs
Taking another stab at the problem, another interesting direction that I see at the intersection of DSLs and LLMs is in investigating new ways of designing DSLs that work with LLM-based coding workflows.
Let me start with a brief interlude on how I have been using LLMs in my own work, and how they have changed how I write certain kinds of code – namely, scripts.
A lot of my programming work on a day-to-day basis involves working on the internals of various verification systems. For these kinds of systems, all the code is pretty complex and intricate, and I really need to write every line myself. In these situations, LLMs really aren't that helpful and any LLM-generated code usually fails to maintain important invariants of the system and use the appropriate APIs.
In contrast, scripts, are things that I write fairly infrequently, are usually one of, and something where using LLMs has substantially changed the way in which I write these programs.
Here's an example of a prompt that I recently wrote to generate some Python code to do some basic data analysis:
- write a massively parallel script that iterates through all thy files in
afp-versions, runs the functionsplit_filewhich you pass in the text contents of the file which returns a pandas df with the columnsname,start_line,end_line,first_word- for each file, record: version (name of immediate subdir under
afp-versionsthat we are in), and project, (the thy files will be under a subdir thys after the verison, so the project is the immediate subdir under that. (extend all rows in the df returned bysplit_filewith these params)- iteratively merge all of these files into a single dataframe incrementally and with restarting, and show progress using tqdm, and use threadpool for parallelism
Now the description above mostly explains what this code was meant to do, and the LLM generated code did exactly what I needed it to do.
Now, the interesting thing about this snippet from a language design
perspective is that it generates an "incomplete" program – in
particular, I don't ask the LLM to generate the function split_file,
and instead just give a specification for what its inputs and outputs
will be and as relevant to the rest of the task.
In a broad sense, when I'm interacting with the LLM for these kinds of scrappy one-off scripts, I'm outlining the high level plan, and asking the LLM to generate the glue code, and then manually implementing the "interesting" part of the problem myself.
From a language design perspective, the question that I'd like to pose from these experiences is, how can we incorporate these kinds of workflows into a DSL? Namely, how can we bridge the gap between the formal and informal? My manually written code is in the realm of "formal", and my textual prompt is in the realm of "informal", and in this snippet, I do that by encoding a specification of the formal in the informal as a text component. Can we do this automatically? Can we build DSLs that integrate seamlessly with informal text? Maybe automatically generating the natural language specifications based on the types/analysis that the DSL itself does?
Language Design Direction 3: Language Design for Verified LLM Synthesis
This is probably the most actively being researched of the directions I've covered in this post so far, but another interesting area for Language Design to move towards following the advent of LLMs is towards the design of specification langauges.
So at a high level, since LLMs have been picking up steam, there has been a cottage industry of researchers jumping into the fray of investigating whether we can use verification langauges, such as Dafny or Boogie and so on, to be able to verify the output of LLM-generated code. The first paper I saw in this direction was "Towards AI-Assisted Synthesis of Verified Dafny Methods" (2024), though I'm sure there are now many many more that have been published, and several more in the works.
// Example from Towards AI-Assisted Synthesis of Verified Dafny Methods
method FindSmallest(s: array<int>) returns (min: int)
requires s.Length > 0
ensures forall i :: 0 <= i < s.Length ==> min <= s[i]
ensures exists i :: 0 <= i < s.Length && min == s[i] {
...
}
Instead of just asking the model to generate some code, which may be complex, intricate and contain bugs, the authors suggest instead asking the model to generate programs in verified languages such as Dafny with specifications. This way, users can just look at the specifications to understand what the program does and do not need to understand the LLM code unless the verification fails.1
From a language design perspective, the interesting questions in this domain consist of asking how we can a) integrate these specifications into DSLs? and b) how we can better design our verification DSLs to capture properties of interest in bespoke domains – of course, the properties you care about for a dialog DSL are going to be quite different from one for maybe a packet routing DSL. Can we automatically build specification langauges from the implementation of our language DSL?
Conclusion: Language Design for LLMs
To conclude this article, I think LLMs pose an interesting problem for the DSL designers – the opportunity cost for using niche languages is now substantially increasing, and so we, as language designers, will be held to a higher standard to justify the use of our DSLs. At the same time, they certainly have radically changed the space of what is possible, and also opened up several interesting problems to explore moving forwards.
Main takeway, language design and DSLs will have to adjust for this crazy new world we're living in, and if we're not careful, there's a very real chance the space of language design will stagnate, and we'll lose the diversity of fun and interesting DSLs and everyone will just end up writing Python…